
Creating a Healthcare Data Analytics Clearinghouse
If you’ve recently managed through a major health issue for yourself or a loved one, you know that the experience doesn’t feel very modern. Your data usually doesn’t pass from one healthcare provider to another, so getting a second opinion or seeing a new specialist often means explaining the situation from scratch. What if you accidentally leave out an important detail? What if you’re prescribed a new drug that has a contraindication for another drug you’re already taking?
The back end of healthcare data and research isn’t much better. Society has made some forward progress, for example, in crunching data to enable more tailored cancer treatments (ex: Cleveland Clinic and radiation). But we’ve also had some notable privacy misunderstandings, like the recent criticism of the Google cooperation with Ascension Health.
Society is on the tantalizing cusp of a much bigger breakthrough: freeing up anonymized data at scale for analysis. This is a perfect healthcare example of the original hype around “big data” and “machine learning”. With some technological and legislative innovation, we could unleash world-changing improvements in medical outcomes and lower the cost of care.
Part of the reason that the original big data and machine learning hype hasn’t yet translated into real-world improvements for the average patient is that the data is too fragmented, as shown by the diagram below. Another part of the reason is privacy concerns.
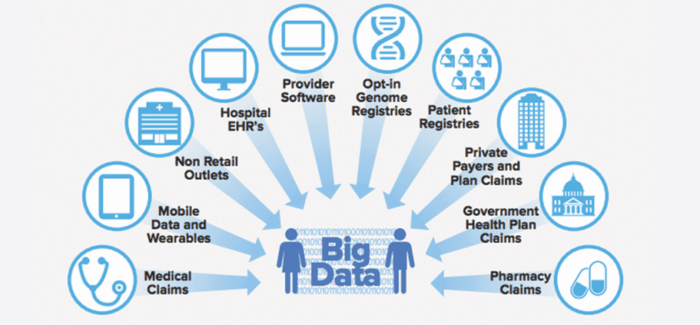
At Prime Data Centers, we’re trying to finally enable that breakthrough with our Sacramento Healthcare Center of Excellence, which would solve both the data fragmentation problem and the privacy problem.
There’s a patient-facing objective and a back-end research objective.
The patient-facing objective is to consolidate the patient’s electronic medical record (EMR) history and make it available in its aggregated entirety to the patient. This would eliminate the problems with partial records and create one whole, coherent, complete health story for each patient and their care providers.
The back-end research objective is to use anonymized healthcare data at scale to empower researchers and doctors to improve treatment outcomes and lower costs.
This post will explain the problems with fragmented medical data and privacy concerns and then outline our solution.
Fragmented/Incomplete Health History Data
Your health history data comes from many sources: your doctors, nurses, insurance companies, clinical labs, pharmacy benefit managers (PBMs), imaging providers, wearable devices, and much more. The diagram below does a good job of showing the complex interrelation of the healthcare data environment.
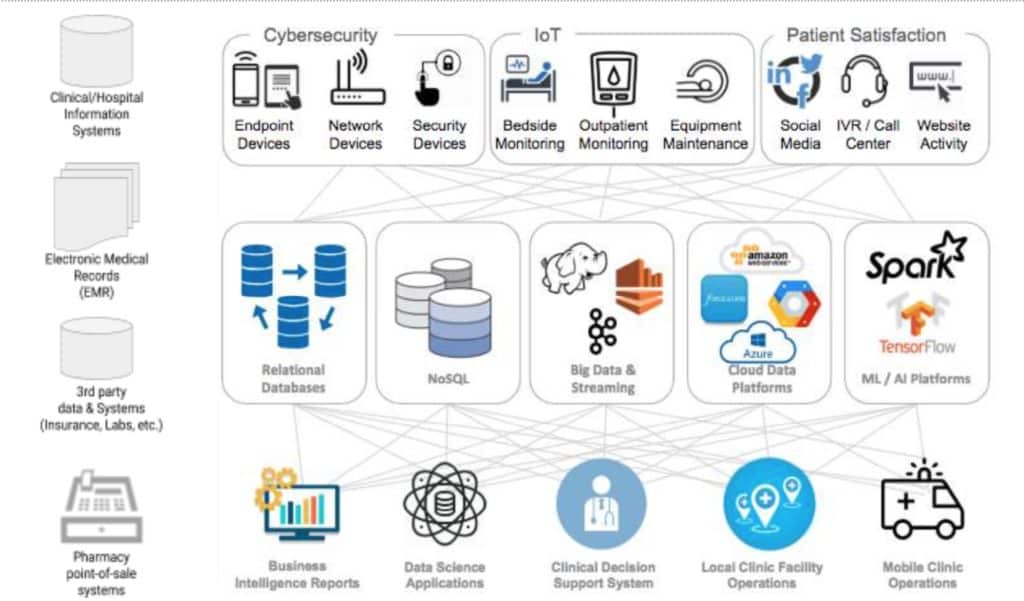
Even within the same company, such as an integrated HMO, internal data silos often prevent the creation of coherent personal health histories. For example, say you visit Hospital A on the west side of town and Hospital B on the east side. Both are managed by the same HMO. But because the two are on different data platforms, or even the same platform, but different database builds, the data can’t get aggregated cleanly.
This puts an enormous amount of responsibility on the patient to manually keep it all coherent. The truth is that the vast majority of us don’t. And who could blame us?
All of this only deals with the diagnosis and treatment history. What about the outcome history? That crucial data is all too often left out entirely.
On the outcome front, morbidity, mortality and cost data mostly reside with the Payor. Providers have limited outcome data from the EMR, mostly from the Coding side. When integrated health systems are empowered to conduct coherent analytics however, we see great results, such as Kaiser Permanente being able to reduce mortality by 20% with predictive analytics. Providers can sometimes infer some outcomes data from the rest of the EMR.
Definitions:
Payor = “a health maintenance organization, insurance company, management services organization, or any other entity that pays for or arranges for the payment of any health care or medical care service, procedure, or product” (source)
Provider = “Under federal regulations, a “health care provider” is defined as: a doctor of medicine or osteopathy, podiatrist, dentist, chiropractor, clinical psychologist, optometrist, nurse practitioner, nurse-midwife, or a clinical social worker who is authorized to practice by the State and performing within the scope of their practice as defined by State law” (source)
Coding = “Medical coding is the transformation of healthcare diagnosis, procedures, medical services, and equipment into universal medical alphanumeric codes.” (source)
PII = Personally Identifiable Information: “information that can be used to distinguish or trace an individual’s identity, either alone or when combined with other personal or identifying information that is linked or linkable to a specific individual” (source)
EMR = Electronic Medical Record: “digital versions of the paper charts in clinician offices, clinics, and hospitals. EMRs contain notes and information collected by and for the clinicians in that office, clinic, or hospital and are mostly used by providers for diagnosis and treatment. EMRs are more valuable than paper records because they enable providers to track data over time, identify patients for preventive visits and screenings, monitor patients, and improve health care quality” (source)
PBM = Pharmacy Benefit Manager: “companies that manage prescription drug benefits on behalf of health insurers, Medicare Part D drug plans, large employers, and other payers” (source)
MMR = Meet Me Room: “otherwise known as ENI (External Network Interface) or MDA (Main Distribution Area), is a relatively small but very important space inside a data center where internet service providers, telecommunications carriers, cable companies, etc. converge to interconnect or cross-connect with one another and exchange data before distribution of services to other areas of the building” (source)
HIT/HES = Healthcare Information Technology/Healthcare Enterprise Software: “Health IT refers to the electronic systems health care providers—and increasingly, patients—use to store, share and analyze information” (source)
ML = Machine Learning: “Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.” (source)
AI = Artificial Intelligence: “Artificial intelligence (AI) makes it possible for machines to learn from experience, adjust to new inputs and perform human-like tasks.” (source)
Payor data can do a good job of inferring what the EMR is. In fact, much of the low hanging fruit in the AI/ML side is mining payor data to infer what condition the patient was in, what the treatment was, and how effective it was (outcomes) both in terms of health and cost.
Now that we’ve covered problems with diagnosis and treatment history and outcome history, we get to the third big missing data/history component: contextual/environmental data.
There’s a lot of missing contextual/environmental data that would help us paint a more actionable picture. If your healthcare providers and the research community knew data like the list below, they’d have a much better understanding of what might have caused your condition and what might help improve it.
- Centers for Disease Control and Prevention (CDC) or World Health Organization (WHO) data
- Weather
- Traffic
- Natural disasters
- Demographics (ex: urban vs rural)
- Air pollution
What Prevents Us from Solving The Fragmented EMR Problem?
There are three key structural blockers to solving the fragmented EMR problem:
Structural Issues
- Technical: How do we pull out homogenous (read: standardized) data from the EMR and from Payor’s outcomes data? It’s very difficult to anonymize and redact health data, partially due to non-standard data hygiene and categorization.
- Legal: How do we protect Personally Identifiable Information (PII) and otherwise comply with legal regulations?
- Organizational: How do various entities work together to share data?
The following examples will demonstrate some of these structural issues.
Ascension Health contracted with Google to data-mine the EMR. While there were strict protocols on which Google employees had access to that data, there are claims that while the Ascension data resided on Google’s cloud platform, Google employees were allowed to download that data. That’s a problem. One way to solve the problem is to create strict protocols on how the data can move and who has access to it.
Another way to solve the problem is to redact PII from the EMR which Google supposedly did with the University of Chicago. The problem is that as we mentioned above, it’s very difficult to reliably remove PII from the EMR at scale.
Another problem is the sheer amount of data. It would take weeks to move several terabytes of data over the internet or even dedicated infrastructure. Not to mention it would be very expensive. Sharing large quantities of data over long distances is simply not practical at the moment. For this reason, many healthcare entities are physically shipping hard drives between locations. In some cases, that has led to huge potential data breaches that have cost the companies a great deal of money and reputation.
Compounding this problem is the nature of the data. It’s a near-infinite resource, which is a good thing. The same dataset can be mined many times depending upon what you are looking for. Making the sharing of data slow, expensive and risky means that entities are not getting a full ROI from their data.
Framing the Solution Space
As we think about tackling these significant challenges, the tendency is to assume that the solutions will be largely digital. We believe that an overlooked area for possible advancement is in the physical world. What if we could build physical spaces in data centers that could greatly facilitate the kind of data manipulation and access required, all while maintaining the highest standards of privacy?
Prime’s Preliminary Solution
We’re among the first to have realized that this is, at least in part, a real estate problem. Our Health Care Center of Excellence is really a Health Care Analytics Data Marketplace in which we create a set of rules for how entities can work with each and how data can be shared. This would be a shared physical space within a data center campus, such as Prime Data Centers’ Sacramento campus. That physical space would be a HIPAA-compliant Meet Me Room (MMR).
Here are the things we can provide:
- Physical and\or logical separation of networks. If Entities A, B, and C want to work together, we can create a network in which the flow of data is predetermined. For example, if A is the data source and B and C are miners, then the data can only go from offsite source to A to B/C. It cannot go in reverse.
- Physical and\or logical separation of compute from the data. We can wall off (or “air gap”) certain servers from the internet altogether, and make them dead ends. In other words, data can pool there but cannot be removed. The algorithms which the servers induce from data mining can be removed from these servers only in very specific ways. We can even remove USB access to these servers.
- Physical and\or logical separation of the data. If need be, we can always just unplug the connection to the databases.
- Third-party physical auditor. We can provide records and act as a reliable third party that can speak to physical and logical separation and also what amount of data moved between servers and over specific cables\networks. We can also speak to which people accessed what pieces of equipment.
A precedent for this type of solution comes from the banking world, in which many banks ask their service providers to create physical or logical separation of their compute to handle each banks’ data. Often, in these cases, whatever compute is in the cloud needs to be taken back into the service providers’ own servers in order to process the banks’ data.
Another way we can solve the problem of physically sharing data is two-fold:
- Provide massive connectivity within the data center (in the form of physical cross-connects). Our cross-connects are fiber, not copper, so that entities can share massive amounts of data with a partner very quickly. No more weeks to share data and no more moving hard drives between facilities.
- Provide easy entry for AI/ML partners. If a healthcare entity wants to run a trial or test out a new partner, all that partner has to do is install an image on our colocation partner’s servers. Then we turn off internet access to those servers, make a physical and\or logical connection between the servers and the data source, and et voila we have an instant partnership with instant data integrity.
Finally, proximity in and of itself leads to more collaboration through the network effect. If there are two payors or two providers in the facility, then it gives more of an incentive for a data-miner to locate there. And vice versa. If there are several data miners there, then that gives incentive for more payors and providers to locate there.
In solving the three main structural blockers we highlighted above (technical, legal, and organizational), a physical solution (real estate) is easier and more immediately actionable than a digital solution.
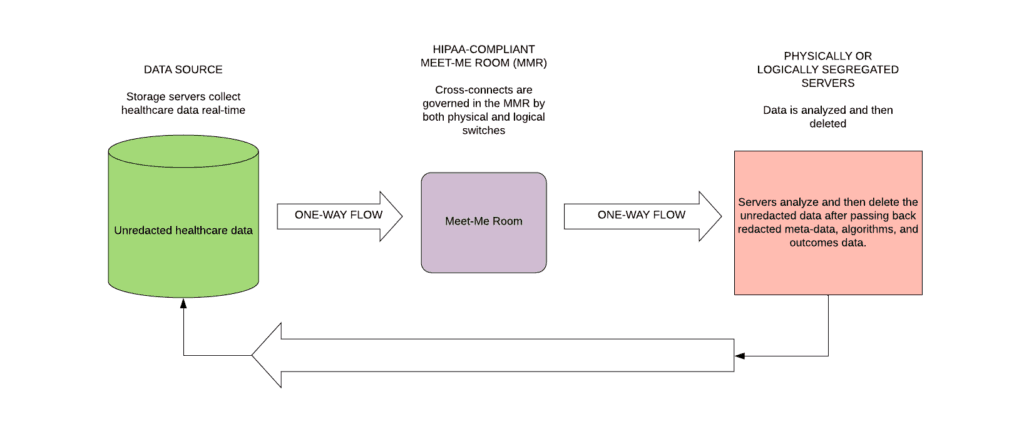
The schematic below shows how a HIPAA-compliant Meet Me Room (MMR) could accelerate the sharing of data between health care entities thus improving both the quality of care and the cost. The new Meet Me Room facilitates the sharing of unredacted data, without taking on unnecessary privacy risk.
Help Us Advance This Solution
If you work in a related field and have input into our proposed solution, we want to hear from you! Either comment below or email us at info at primedatacenters dot com. You can also chat with us on Twitter.
Learn More
McKinsey has several great posts about the long-overdue digital revolution of healthcare. Start with their post entitled “Promoting an overdue digital transformation in healthcare”.
Paddy Padmanabhan wrote a great, short post for CIO.com titled “Healthcare’s digital transformation: 5 predictions for 2020”
We’ve written previously about California Healthcare Data Center Criteria.



